输入
一个包含少量与目标事件相关的信息与大量其他非相关信息的微博评论数据
输出
与目标事件相关的特征词语集合
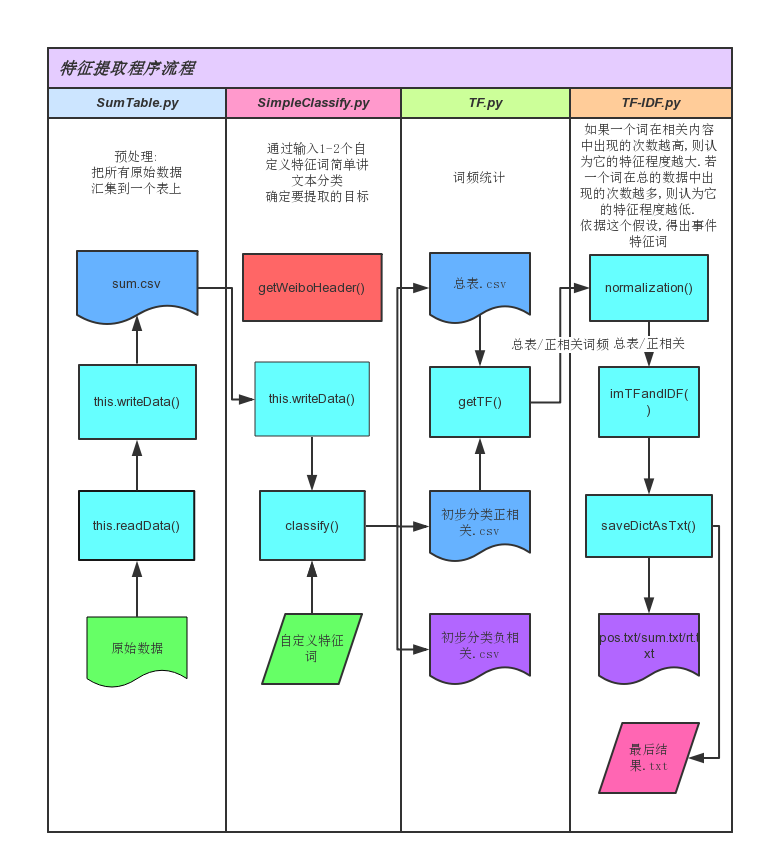
算法思路
如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。即 TF-IDF。
若要使用TF-IDF,我们首先需要一个到多个目标数据(文章),以及更多的其他数据。而我们这里只有一个总的数据集。
针对这个问题,我们通过一到两个与目标事件一定相关的自定义词语(感谢王萍大佬),将总的数据集分为两部分。一部分数据一定包含这两个词语,我们认为这部分数据与该事件一定相关,称为“初步分类正相关”。另一部分则不全包含这些词语,认为这部分数据不具有代表性,称为“初步分类负相关”。最后将之前的总的数据集称为“总表”。利用这个方法,我们获得了目标数据与总的数据集(之前已存在)。
考虑到IDF的公式idf = log(n / docs(w, D))要求有更多的其他数据,我们这里只有一个其他数据(即“总表”),所以仍然无法使用TF-IDF。这里有两种解决方案:
1.将“总表”中的每一个评论作为一个单独的“其他数据”,则为了平衡数据,相应的我们需要将“初步分类正相关”中的每一个评论作为一个单独的目标数据。这样提取出的特征只可代表这一条评论,无法代表整个目标事件。此外这种从一小段话中我们只能提取一小部分词或短语,数据量很小,很多情况下甚至不会有一个词语出现重复,这种情况下TF-IDF的结果是很不可信的。
2.可以寻找一个参数,使得IDF在只有一个其他数据的情况下得到的结果通过这个参数仍可与TF正常结合。
方案1有明显的缺陷,故舍弃。而方案2中的参数寻找也不并不简单,尤其是对于这个数据无任何明显特征的项目。
基于TF-IDF的基本原理,我们将“初步分类正相关(目标事件)”统计出的词频作为TF,将“总表(总的数据集)”统计出的词频作为IDF,并将TF与IDF的乘积关系变为和的关系,即TF-IDF(减法)。同时,在进行求和运算前,为了使得TF、IDF能在同一尺度上进行比较,对二者进行归一化处理。最后得到一组关于单词与数字的键值对,我们将每个单词对应的数字作为这个单词的分数,对分数进行降序排列,得到一组单词短语的排序表。排序靠前的单词组成的集合可以看做与目标事件相关的特征词语集合。
对于这种基于TF-IDF的特征提取算法,这里称作改进型TF-IDF算法。

下一步骤
sir模型
打算采用数学建模sir模型,SIR模型中的S表示易感者(关注者),I表示感染者(发评论),R表示移出者(转发/僵尸粉)。
根据微博评论人员统计,看看能不能统计出地域影响力
优化算法——模拟退火算法
模拟退火算法(Simulated Annealing, SA)的思想借鉴于固体的退火原理,当固体的温度很高的时候,内能比较大,固体的内部粒子处于快速无序运动,当温度慢慢降低的过程中,固体的内能减小,粒子的慢慢趋于有序,最终,当固体处于常温时,内能达到最小,此时,粒子最为稳定。模拟退火算法便是基于这样的原理设计而成。

