https://www.bilibili.com/video/BV1ts4y1T7UH https://mp.weixin.qq.com/s?__biz=MzIxODUzNTg2MA==&mid=2247485342&idx=1&sn=770152ca8a00f2e3d87ed2a09e131e11
生成式AI动画
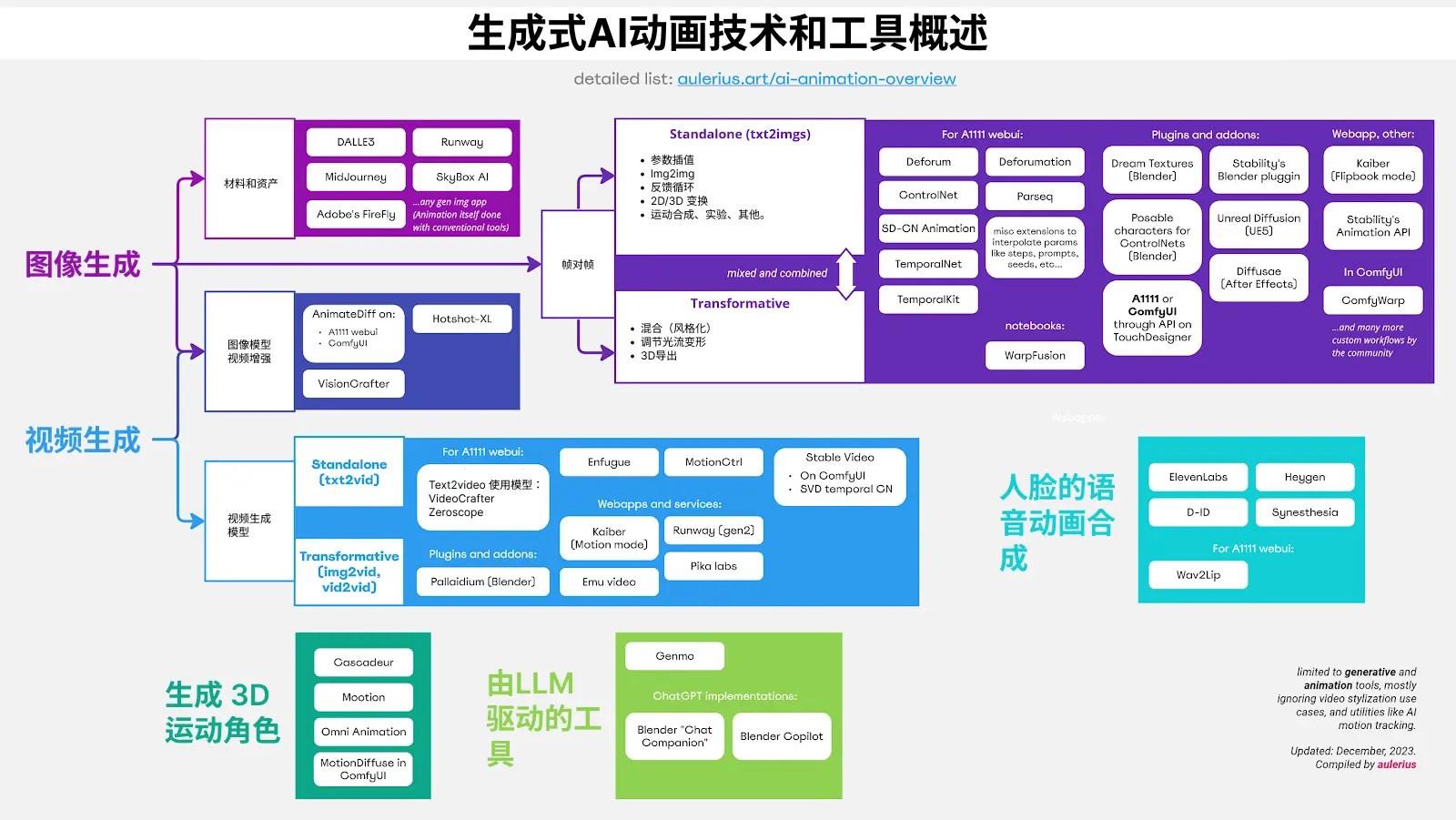
- 图像生成: 依赖于使用生成图像人工智能模型的技术,这些模型是在静态图像上进行训练的。
基本原理:以图像为样本,使用扩散图像模型逐帧生成动画帧,或者借助拟态进行图像变化(光流、3D衍生等)
- 视频生成:
这类技术依赖于生成视频的 AI 模型,这些模型要么是通过动态视频进行训练的,要么是在神经网络层面增强了对时间的理解。
目前,这些模型的一个显著特点是它们通常只能处理非常短的视频片段(几秒钟),这主要是受限于 GPU 上的视频内存。然而,这种情况很可能会迅速进步,而且已经有方法可以把多个短片拼接成更长的视频。
类似于生成式图像模型中的图像到图像过程,在视频模型生成(去噪)输出的同时,除了文本提示之外,还可以将输入视频信息融入其中,但其根本还是借助视频模型,比如之前各种舞蹈的视频,特效模型
chatgpt
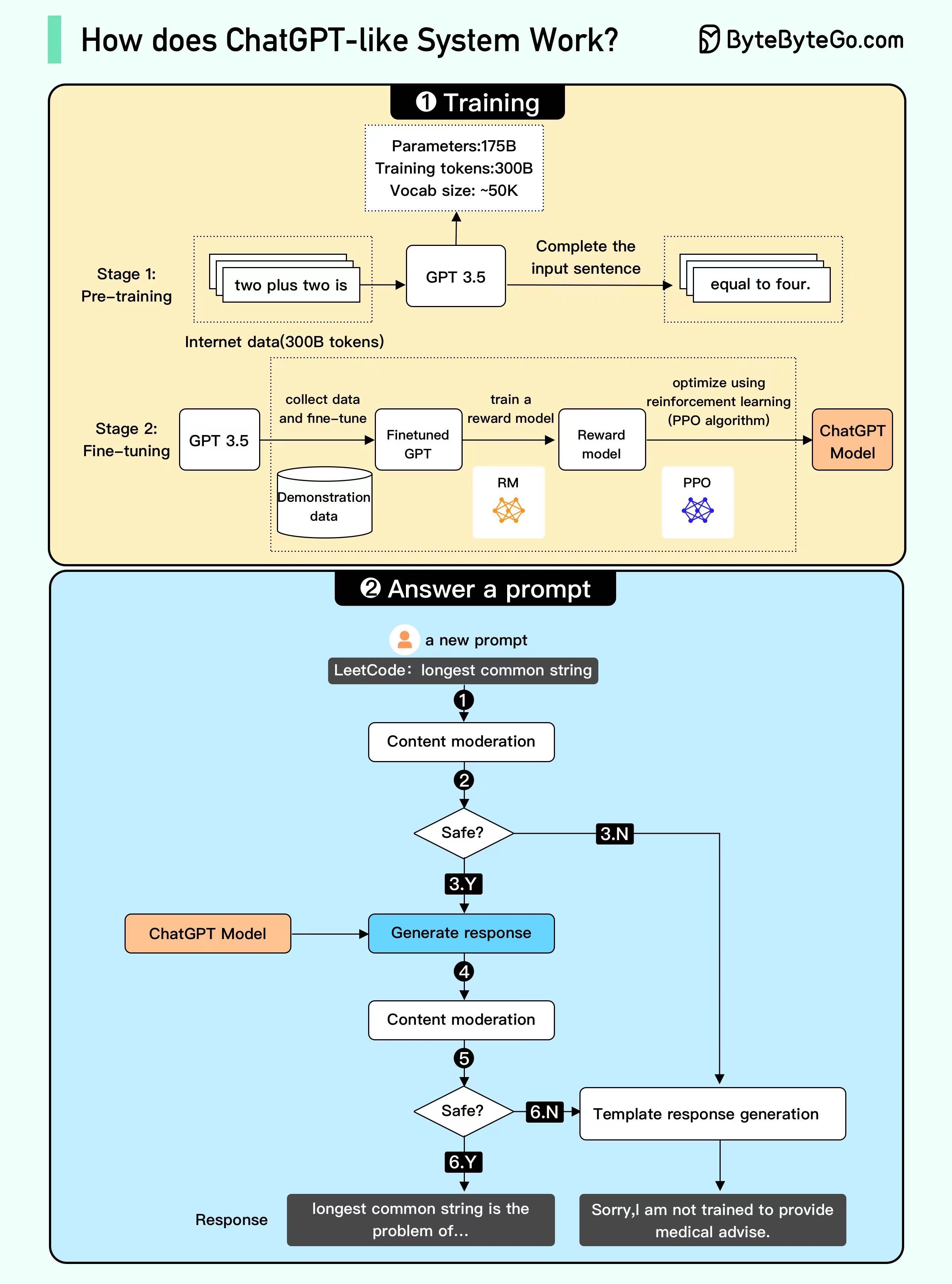
ChatGPT类似系统如何工作的信息图,它分为两个主要部分:训练(Training)和回答提示(Answer a prompt)。
一、训练(Training)
这个部分展示了系统如何被训练以回答问题或执行任务。它分为两个阶段:
1、预训练(Pre-training):
-
参数:175B(意味着模型有1750亿个参数)
-
训练令牌:300B(使用了3000亿个令牌来训练模型)
-
词汇大小:约50K(模型识别和使用的词汇约有5万个)
这一阶段使用了从互联网上收集的3000亿个令牌的数据来训练。例如,它可能被训练在看到“two plus two is”时完成句子为“equal to four”。
2、微调(Fine-tuning):
在这个阶段,使用特定的示例数据来微调GPT-3.5模型,这些数据是为了改进模型在特定任务上的性能。
然后使用奖励模型(RM)来进一步训练GPT模型,奖励模型会评估GPT模型的输出并给予反馈。 最后,使用强化学习(PPO算法)来优化模型,使其在实际应用中表现更好。
二、回答提示(Answer a prompt)
这个部分说明了当系统收到一个新的提示或问题时会发生什么。
-
内容审核(Content moderation):首先,系统会对输入的提示进行内容审核,以确保安全合规。
-
安全检查(Safe?):如果内容被认为是安全的,流程会继续(Y),如果不安全(N),则不会生成响应。
-
生成响应(Generate response):如果内容审核通过,ChatGPT模型将生成响应。
-
再次内容审核(Content moderation):生成的响应会再次经过内容审核。
-
二次安全检查(Safe?):如果审核通过(Y),响应将被发送给用户。如果不通过(N),系统可能会生成一个模板响应。
-
响应(Response):最后,如果所有审核都通过,系统会提供一个响应,例如,“longest common string is the problem of…”。如果不通过,系统可能会回答,“Sorry, I am not trained to provide medical advise.”

