AgentVerse
- 由清华大学、北邮等高校研究团队发布的AI多智能体协作模拟框架
- 模拟多种社会实验场景,如NLP课堂、囚徒困境、软件设计等 🔗详细:github.com/OpenBMB/AgentVerse 🔗Tweet:twitter.com/xiaohuggg/status/1701234611806691810?s=20
工业仿真或者家居设计可使用
Meshy.ai
- 用于3D创意的AI生成工具箱
- 功能:2D转3D纹理、文本提示生成3D纹理、AI3D纹理工具等
- 使3D工作流程更加高效 🔗详细:Meshy.ai 🔗Tweet:twitter.com/xiaohuggg/status/1701194691973386443?s=20
怎么感觉最后都是为图像标注做准备。。。
Stability AI推出AI生成音乐平台:Stable Audio:
- 描述:输入描述性文本提示和音频长度生成音乐和音效
- 特点:免费版生成20秒音乐,Pro版可生成90秒 🔗网站链接:http://stableaudio.com 🔗推文链接:https://x.com/xiaohuggg/status/1701884386910871953?s=20
场景非常好,可做成SDK适配一切剪辑软件和短视频平台
🎥Flowjam 产品视频库:
- 提供各种产品宣传视频,为小公司和独立开发者提供灵感
- 价格合理,支持无限次修改的定制开发服务 🔗详细:https://x.com/xiaohuggg/status/1702973829956657288?s=20
下次做内部宣传视频、发布会、xx纪念就是你了
Google Bard 更新:
- Bard发布了一个新的AI模型并与其他Google服务集成
- 新功能:“Google it”功能的优化与扩展,支持40种语言 🔗详细:https://x.com/xiaohuggg/status/1704103089203249350?s=20
真的能all in one么?
ElevenLabs “Projects” 功能:
- 用于生成和编辑长篇音频
- 功能:一键全文转换、发言者分配、重新生成音频片段、插入暂停等 🔗官方介绍:https://elevenlabs.io/projects 🔗https://x.com/xiaohuggg/status/1704330887683604991?s=20
转的效果还挺不错的,完全没有tts那股硬邦邦的吐字感
Flourish:
- 轻松地将你的数据转化为令人惊叹的可视化效果的工具
- 功能:创建数据图形和动画故事、无需编码或安装、无缝嵌入、品牌定制 🔗 详细:http://flourish.studio 🔗 https://x.com/xiaohuggg/status/1704860235817697384?s=20
这个还是比较适用于2B业务,往小了说就是一个轻量级业务看板的需求神器 霍,生成的图还真是不错
微软365AI落地新功能看了超心动
🔥 copilot加入全家桶9月26日起海外可以正式使用 https://x.com/xiaohuggg/status/1704886721912221960?s=20
365有点杀疯了.。
AI 图像修复工具、模型大全:
- 一些图像修复工具+模型 🔗详细:https://x.com/xiaohuggg/status/1698981381022581104?s=20
maybe后面有用
GPT-4V(ision) Update:
- 今天OpenAI发布的模型其实叫GPT-4V(ision)。
- OpenAI放出了19页的GPT-4V(ision)报告。
- GPT-4V可以为其500,000名盲人和低视力用户提供前所未有的工具。
- OpenAI还研究了模型的基于地理位置的能力,以及模型破解CAPTCHA的能力。 🔗详细:https://cdn.openai.com/papers/GPTV_System_Card.pdf
高级地图。。开玩笑了,这个军工yu适用面更广,比如。。daodan制程?
Manga-Image-Translator:一个开源的漫画图片翻译器
- 能够自动翻译漫画图像中的文本,当然普通的图片也可以。翻译完成后在图像在原位置替换译文。干净简洁,速度很快。
- 主要支持日语,汉语、英文和韩语。 🔗 http://cotrans.touhou.ai
真正的算命和占卜模型 - Mistral Trismegistus 7B::
- 适合推销??? 🔗 https://x.com/xiaohuggg/status/1714846126371926086?s=20
Face Swapper:AI换脸工具:
- 视频领域 https://icons8.com/swapper
bigpixel.cn
- 360视图看世界 https://bigpixel.cn
Insanely Fast Whisper:极速音频转录工具:
- 能在98秒内转录300分钟音频。
- 基于OpenAI的Whisper Large v3模型改进。
- 支持多版本和不同配置,目前只支持Nvidia GPU。 🔗 https://t.co/qBVm8NoeqF
LCM即时绘画,体验所见所得:
- LCM LoRA支持即时绘图生成,体验直观。
- 在线体验地址提供直接访问。
- 清华大学@SimianLuo开发,加速稳定扩散模型运行。 🔗 https://huggingface.co/spaces/ilumine-AI/LCM-Painter
【重点】GPT-Crawler:知识库自动爬虫工具:
- 爬取网站内容生成JSON文件。
- 方便创建自定义GPTs知识库。 🔗 https://github.com/BuilderIO/gpt-crawler
统一写爬虫轮子库?
Flowty Realtime LCM Canvas:实时草图转图像:
- 在MacBook上运行的实时草图转图像开源程序。
- M2 Max配置下每次渲染需1.2秒。
- 可调整模型ID和参数以优化结果。 🔗 https://github.com/flowtyone/flowty-realtime-lcm-canvas 🔗 https://x.com/xiaohuggg/status/1727622388358267384?s=20
MCVD:通用的视频生成模型:
- 能创造全新视频、预测未来画面、重建过去画面。
- 在视频片段之间创造中间画面。 🔗 https://x.com/xiaohuggg/status/1727609231866773878?s=20
更多关于Q*(Q-Star)的信息:
- 可能具备自主学习、自我改进能力。
- 可自主决策,或已有轻微自我意识。
- GPT-Zero项目解决数据生产问题。 🔗 https://x.com/xiaohuggg/status/1727568964065382411?s=20
将网站变成播客/有声读物:
- 利用OpenAI的TTS语音API。
- 自动识别网页内容语言并朗读。
- 目前为Demo测试,需OpenAI API。 🔗 http://readany.vercel.app
ElevenLabs推出AI语音转换器:Voice-Changer:
- 转换不同声音或角色。
- 控制情感和传递方式。 🔗 https://x.com/xiaohuggg/status/1727519973718040838?s=20
draw-fast:草图到实物图渲染工具
- 实时将草图转换成真实图像。
- 项目基于 @fal_ai_data 的 LCM 模型。 🔗 https://github.com/tldraw/draw-fast
【重点】今日无题,学学论文
https://waytoagi.feishu.cn/wiki/OCXXwcOk1iDsDekyNgFcXOEVnne
https://www.bilibili.com/read/cv28006457/?jump_opus=1
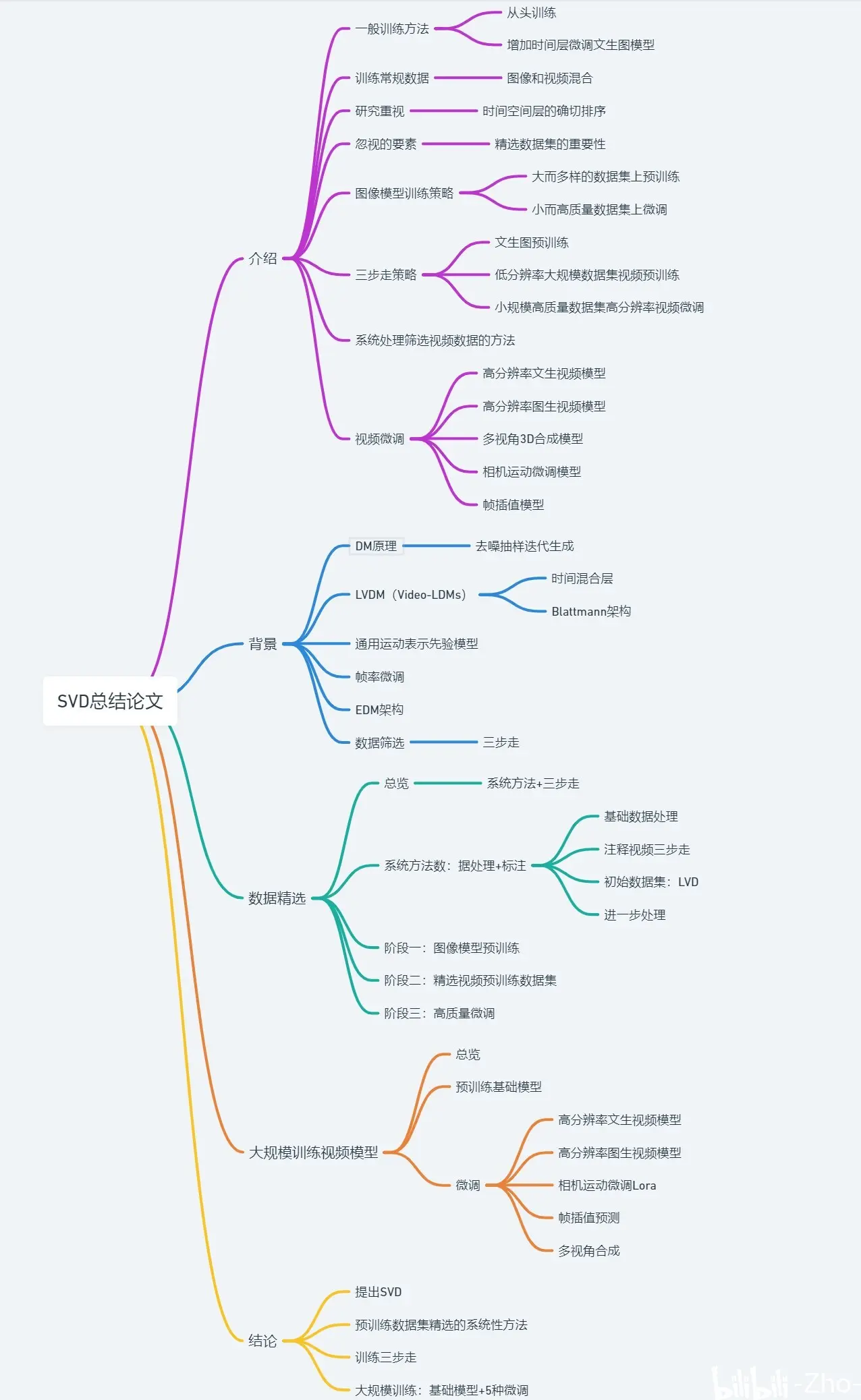
OpenAI大模型原理和训练过程

DREAM-Talk - 照片说话项目:
- 字节跳动开发,单张图片生成说话面部动画。
- 支持多种情感表达和多语言。 🔗 https://magic-research.github.io/dream-talk/
OpenSaaS - 免费开源的SaaS模板:
- 提供预配置的功能丰富平台,便于构建应用。
- 包含用户认证、内置博客、支付系统等。
- 特别适合小型团队和个人开发者。 🔗 http://opensaas.sh
【重点】AppAgent - 人类操作模拟AI:
- 自主学习模仿人类手势,执行多种手机任务。
- 由腾讯和德州大学达拉斯分校研究团队开发。 🔗 https://appagent-official.github.io
MJ 6.0 牛逼。。。。。
Prompt:Minimalist editorial photo, <人物姓名> portrait. --ar 4:3 --v 5
DreamTuner 图像生成工具:
- 由字节跳动开发,通过单张图片创造主题一致的新图像。
- 可以将物体置入不同场景或添加元素。
- 适合创造个性化主题图像。 🔗 https://dreamtuner-diffusion.github.io
ControlRoom3D 3D房间设计:
- 根据布局和风格描述设计3D房间模型。
- 自动调整房间深度和物体表面细节。 🔗 https://jonasschult.github.io/ControlRoom3D/
AI视频搜索引擎:
- 搜索引擎允许用问题查询视频。
- 可与视频进行互动对话,自动总结内容。
- 已索引约17245个YouTube视频,计划扩展到TikTok。 🔗 https://avse.vercel.app
微软新手AI课程
丢给老爸老妈看看能不能看懂 https://github.com/microsoft/generative-ai-for-beginners
扫描物体生成3D模型:
- 使用APP扫描物体,完成3D全貌捕获。
- 创建AR QR码,展示物体于任何地点。
- 苹果新品官网展示中应用此技术。
好像摆摊不错 🔗 https://ar-code.com/blog/digitalizing-restaurant-menus-with-augmented-reality-qr-codes
Search2AI联网服务:
- 为ChatGPT第三方客户端提供联网服务。
- 自动判断用户意图,决定是否联网查询。
- 支持Google和Bing,计划扩展更多服务和场景。 https://github.com/fatwang2/search2ai
Assistive Video一个新的AI生成视频的工具:
- 通过文字提示或图片生成视频内容。
- 用户可控制视频质量和内容一致性。
- 体验地址:https://assistive.chat/product/video
Figure-01机器人自学煮咖啡:
- Figure-01机器人利用神经网络通过观察视频录像学会煮咖啡。
- 使用端到端AI系统,无需编程。
- FigureCEO Brett Adcock宣布AI突破。 🔗 https://x.com/xiaohuggg/status/1743998321977672058
Clipper:HTML到Markdown转换器:
- 简易将网页内容转换为Markdown格式。
- 包含爬虫功能,剪辑并转换网站内容。
- 支持多种输出格式,适用于数据提取。 http://github.com/philschmid/clipper.js/tree/main
Magnific AI图像升级器:
- 图像提升至10K级别。
- 支持Midjourney图像放大8倍。
- 新特性:Fractality滑块。 🔗 https://twitter.com/xiaohuggg/status/1744559983243694528?s=20
BetterYeah AI
- 内置数十个国内外大模型:内置ChatGLM、阿里通义千问、百度千帆等国内外知名大模型,无需单独分别申请,一键使用
- 可视化workflow:用户友好的界面,支持各种开发节点,如LLM、Memory、Code和API等,5分钟就可以快速搭建一个AI应用
- 简单易用的数据集:为您提供一系列数据处理工具,包括数据清洗、自动向量化等
- 灵活的开发运维:全方位的开发运维服务,如在线调试、日志追踪、一键发布等 🔗 https://ai-docs.betteryeah.com/guide/dataset-quick-start/
Personalized Restoration:面部图像精准恢复和个性编辑技术
- 高效恢复受损图像细节,保留个人面部特征。
- 支持面部交换和文本引导编辑功能。
- 结合文本引导和模型调整的双轴方法。 🔗 Personalized Restoration via Dual-Pivot Tuning
Topaz Video AI 4发布,提升视频至16K分辨率:
- 引入24种时序感知AI模型。
- 电影级噪声去除技术。
- 单次购买299美元。 🔗 https://topazlabs.com/topaz-video-ai
LEGO多模态理解模型:
- 由字节跳动和复旦大学开发。
- 支持图像、音频、视频输入,具备精准定位能力。
- 可用于识别图像中物体位置,视频事件时间点,音频声源。 🔗 https://x.com/xiaohuggg/status/1745763961323262056?s=20 🔗 https://lzw-lzw.github.io/
Surya:多语言文档OCR工具:
- 提供准确的逐行文本检测和识别。
- 特点:逐行文本检测,文本识别,表格和图表检测(即将推出)。
- 支持语言:包括英语、中文、日文、印地语等。 🔗 https://t.co/HvqtVwNZ7p
Portkey AI网关 - 连接多种AI模型的工具:
- 提供简单API接口,连接超过100种大语言模型。
- 包括OpenAI、Anthropic等知名AI服务。
- 体积仅45kb,处理速度提升9.9倍。
- 灵活配置,方便切换不同AI服务。 🔗 https://github.com/Portkey-AI/gateway
大厂入局
PhotoMaker - 创造个性化人物图像:
- 可以根据文字描述生成人物照片。
- 能混合不同人物特征创造新形象。
- 改变照片中人物的性别、年龄。 🔗 https://photo-maker.github.io
不错的博客
24、25 年会是下一代浪潮最关键的两年 | AI 年终复盘
https://www.xiaoyuzhoufm.com/episode/65a2a75fb5e4856c70801eba
文生图/文生视频技术发展路径与应用场景
26种多模态大模型研究报告:
- 全面分析市面上的26种多模态大语言模型(MM-LLMs)
- 涵盖模型架构、训练流程设计
- 每种模型具有独特设计和功能 🔗 https://arxiv.org/abs/2401.13601
OpenAI推出新一代嵌入模型
- 新嵌入模型:text-embedding-3-small和text-embedding-3-large。
- 新模型性能普遍优于上一代,特别是在多语言检索方面。
- GPT-4 Turbo预览版模型更新,提高代码生成等任务的完成度。 🔗 https://x.com/xiaohuggg/status/1750688990104330481?s=20
Adept Fuyu-Heavy:多模态数字代理模型
- 世界第三大多模态模型,擅长理解用户界面。
- 可以解释和操作各种软件和应用程序的界面。
- 帮助执行任务如自动化流程、响应查询等。 🔗 https://x.com/xiaohuggg/status/1750704152605499508?s=20
重要-ChatGPT推出Mention功能
- Mention可以在ChatGPT的聊天窗口中通过@来直接召唤任何GPTs,就像Discord里面召唤其他机器人一样
- 这样不用来回切换窗口就能完成不同任务 这样可以实现调用多个机器人的联动操作,完成一个任务
这是生态建立的里程碑,想象一下,以后所谓的流程引擎可以不通过图形化拖拉拽操作(没错,现在就是这么死板),后面是多接口自发互相协调,是自发!
百川智能的Baichuan 3模型:
- 中文任务评测表现卓越,超越GPT-4。
- 在医疗领域和中华传统文化理解方面表现突出。
- 引入创新技术,提高训练效率和数据质量。 🔗 https://x.com/xiaohuggg/status/1751830719222124727?s=20
SliceGPT - 微软开发的大语言模型压缩方法:
- 在保持高性能的同时大幅减少模型参数。
- 允许在更少的GPU上运行,提高运行速度。
- 显著降低了在消费级GPU上的总计算量。 🔗 https://arxiv.org/abs/2401.15024
AnyV2V视频编辑框架:
- 无需训练,与任何模型集成。
- 支持文本提示的各种视频编辑,包括风格转换和面部替换。 🔗 https://tiger-ai-lab.github.io/AnyV2V/
Apple Vision Pro教育应用:
- Insight Heart应用程序提供360度心脏学习体验。
DALL-E 3图像再编辑:
- 支持对生成图像的选定区域进行修改。
- 引入编辑器增强图像编辑能力。
- 处于灰度测试阶段。 🔗 https://x.com/imxiaohu/status/1772470419435536696?s=20
Hand Talk:
- AI手语翻译,联合国最佳社交应用, 🔗 https://www.handtalk.me/en/app/
OpenAI 发布 GPT-4-Turbo 正式版:
- 全面开放,自带视觉能力,128k上下文。
- 训练数据截至2023年12月,价格保持一致。 🔗 https://x.com/imxiaohu/status/1777822285732438513?s=46

